A new paper is accepted in the Complexity journal, where the authors are: Carlos Mazano, Claudio Meneses, Paul Leger (https://doi.org/10.1155/2021/6760920 – To appear). Here is the abstract:
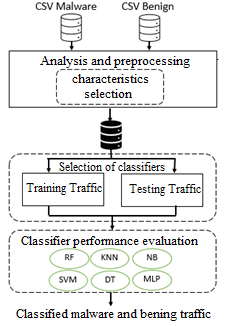
Malware is a sophisticated, malicious, and sometimes unidentifiable application on the network. The classifying network traffic method using machine learning shows to perform well in detecting malware. In the literature, it is reported that this good performance can depend on a reduced set of network features. This study presents an empirical evaluation
of two statistical methods of reduction and selection of features in an Android network traffic dataset using six supervised algorithms: Naïve Bayes, Support Vector Machine, Multilayer Perceptron Neural Network, Decision Tree, Random Forest, and K-Nearest Neighbors. The Principal Component Analysis (PCA) and Logistic Regression (LR) methods with p-value were applied to select the most representative features related to the time properties of flows and features of bidirectional packets. The selected features were used to train the algorithms using binary and multiclass classification. For performance evaluation and comparison metrics, precision, recall, F-measure, accuracy, and area under the curve (AUC-ROC) were used. The empirical results show that Random Forest obtains an average accuracy of 96\% and an AUC-ROC of 0.98 in binary classification. For the case of multiclass classification, again Random Forest achieves an average accuracy of 87\% and an AUC-ROC over 95\%, exhibiting better performance than the other machine learning algorithms. In both experiments, the 13 most representative features of a mixed set of flow time properties and bidirectional network packets selected by LR were used. In the case of the other five classifiers, their results in terms of precision, recall, and accuracy, are competitive with those obtained in related works, which used a greater number of input features. Therefore, it is empirically evidenced that the proposed method for the selection of features, based on statistical techniques of reduction and extraction of attributes, allows improving the identification performance of malware traffic, discriminating it from the benign traffic of Android applications.