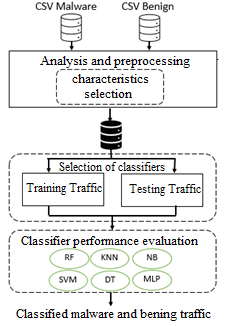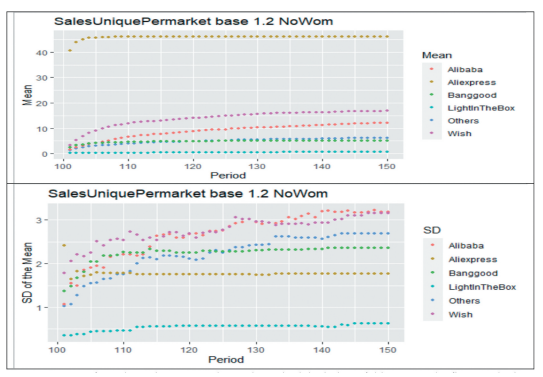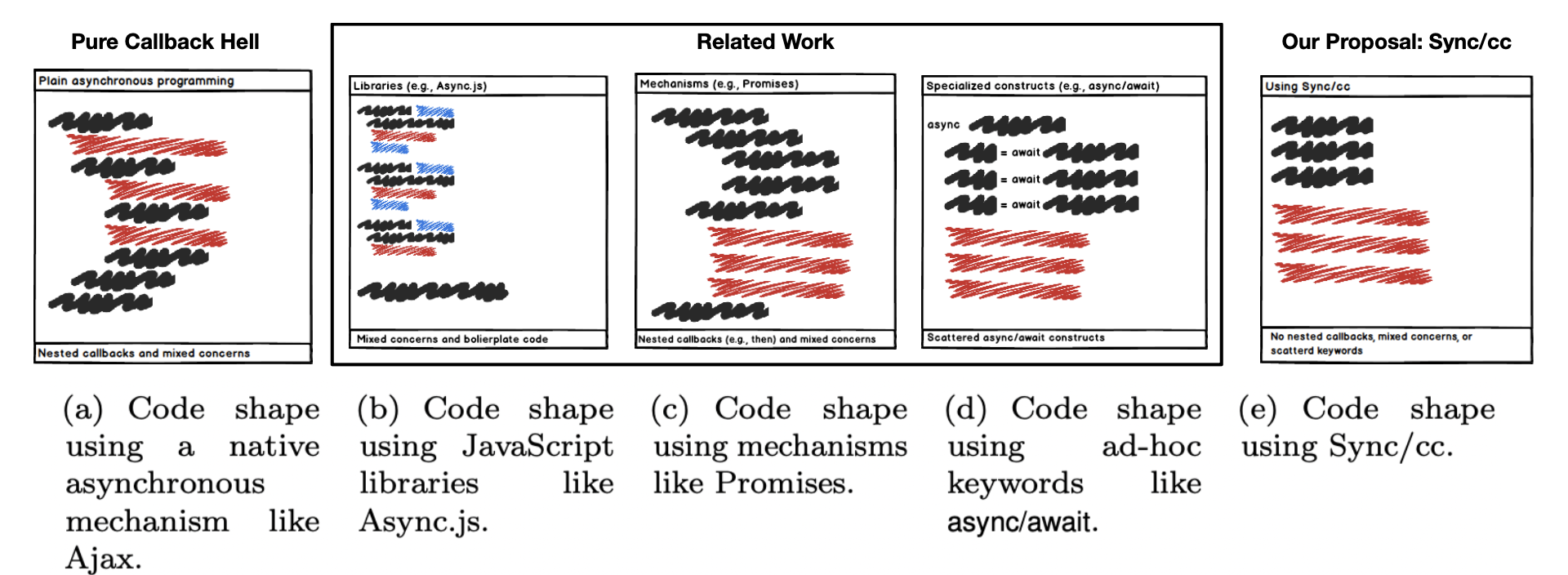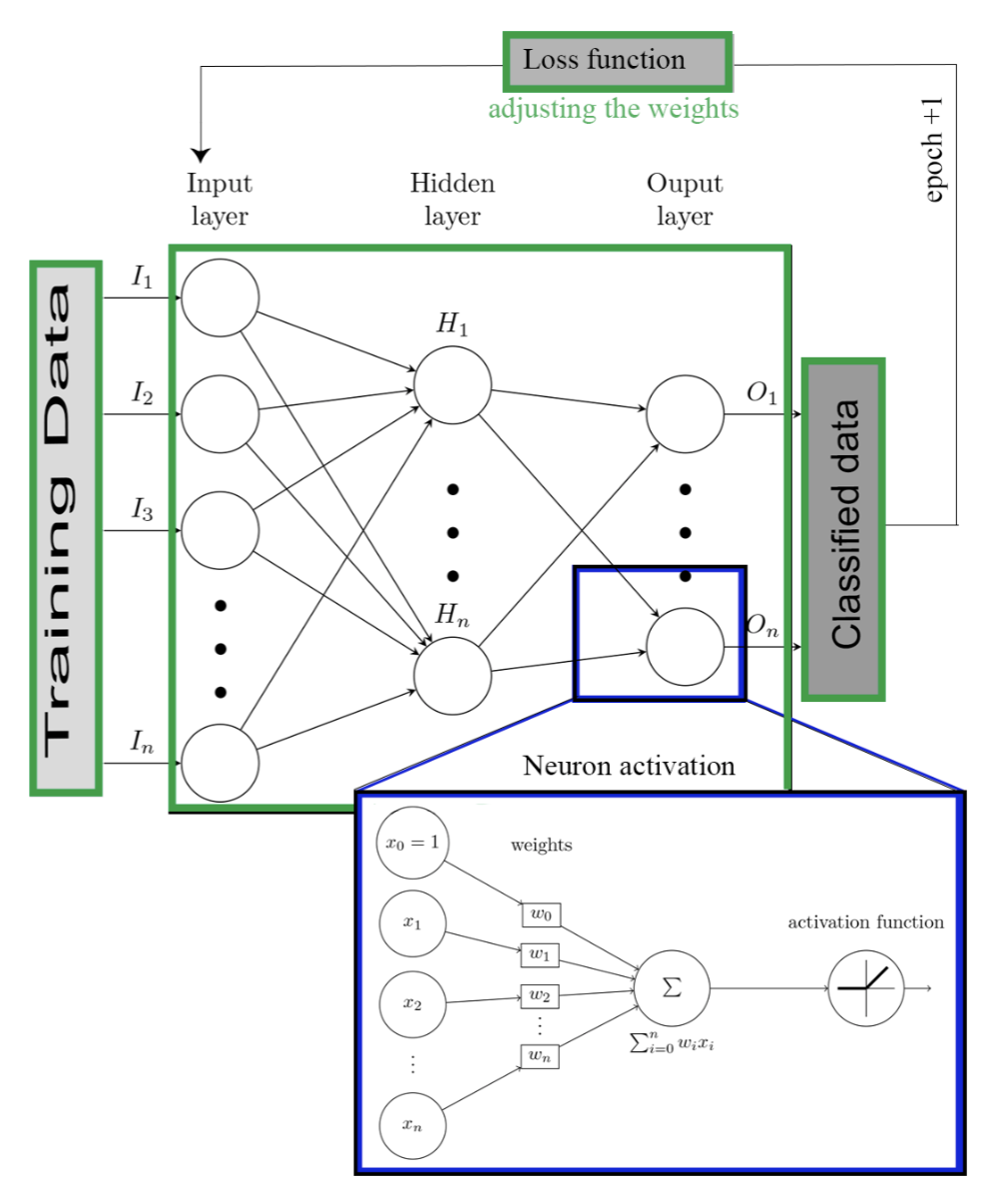
A new paper is accepted in the Complexity journal, where the authors are: Juan Sebastian Sosa, Paul Leger, Hiroaki Fukuda, Nicolás Cardozo (https://doi.org/10.1155/2021/6760920 – To appear). Here is the abstract:
Managing mobile ad hoc systems is a difficult task due to the high volatility of the systems’ topology. Ad hoc systems are commonly defined by means of their constituent entities and the relationships between such entities, however, a formal specification and run-time execution model is missing. The benefit of a formal specification is that it can enable reasoning about local and global system properties, for example, determining whether the system can reach a given state. We propose a Petri net-based specification and execution model to manage ad hoc distributed systems. Our model enables spontaneous communication between previously unknown system components. The model is locally equivalent to standard Petri nets, and hence could be used for the verification of properties for system snapshots static with respect to connections and disconnection, in which it is possible to analyze liveness, reachability, or conflicts. We validate the usability of our distributed ad hoc Petri net model by modeling distributable systems as described by existing distributed Petri nets approaches. Additionally, we demonstrate the applicability and usability of the proposed model in distributed ad hoc networks by implementing the communication behavior of two prototypical ad hoc network applications, disaster and crisis management, and VANETs, successfully validating the appropriate behavior of the system in each case.